Quick question about annotations created using the hypothesis plugin and the new cloning feature. I haven’t done much testing on this yet, but am curious to know what happens to annotations made on a public Pressbook (with the hypothesis plugin activated) when that book is cloned to a new PB instance? Does Pressbooks use the canonical or alternate link methods described here: Guidance for Web Publishers : Hypothesis , for example?
I just did a brief test using https://wisc-dev.pb.unizin.org/ronsnardvieille271dev/. When I cloned that book from its original location to https://wisc.pb.unizin.org/frenchcrs, the annotations did not appear to come along with it. Does anyone have suggestions for how to preserve annotations upon cloning?
Hi Steel,
My understanding is that neither a canonical link nor an alternate link would be appropriate to refer back to a source book. If Book A is cloned as Book B and then modified or expanded, the appropriate canonical link for Book B would be to Book B, not Book A; as for alternate, it’s a way of signifying a different format (e.g. an RSS feed) rather than a different instance or variant of content. We intend to foreground explicit “version tracking” of cloned books in the new webbook theme, so that the Schema.org isBasedOn property is highlighted both on the cover page in a human-readable format and in the metadata of cloned web books (including tracking a clone of a clone back to the original source). However, this doesn’t appear to solve the issue.
Furthermore, my concern about linking two books explicitly would be that annotations on one book and annotations on the cloned/modified book would get mixed together. The correct approach would be to somehow bring annotations along to the cloned book, but I haven’t the first idea how to do this as they aren’t stored in Pressbooks.
Phew, this is a tricky issue! In my reading of the document linked in the original post, the ‘alternate’ link option came closest to describing what I imagined the relationship to be, though I agree that it’s not an ideal description, particularly if the cloned text begins to diverge significantly from the original. My initial thought was to wonder whether it might be possible/advisable to add an option (via a plugin or network setting perhaps) that when checked (by a network admin) would, at the time of cloning, automatically to add an ‘alternate’ reference pointing back to the source to the head of the various parts of cloned books. I think this might be a question for me to raise with the hypothesis folks as well. I’ll write to Jeremy, Robert, and Jon tomorrow to see if they have any bright ideas.
Ned—do you know if annotations flow both ways (if connected via canonical or alternate links in the header of the ‘cloned’ book)? I assumed that annotations would come into the child/copy from the ‘parent’, but that annotations made on that copy would not automatically propagate the other way, but I don’t know why I’m assuming that’s the case. It occurs to me know that linking them in this might might also mean that future annotations to the parent would dynamically/automatically show up in the child/link copy as well, but I’m not sure about that assumption either. As I’m writing this, I realize that I need to better understand how the annotation model used by hypothesis works.
And Jon Udell from Hypothesis has already written a detailed reply: https://blog.jonudell.net/2017/11/28/syndicating-annotations/
Ok-I’ve read and digested Jon’s reply. I think that their support for Dublic Core metadata offers an interesting possibility. I note that the guidance for web publishers page at hypothesis suggests that “Publishing metadata about your content is a useful thing to do. We encourage you to publish what makes sense in your context, and to let us know if there are types of metadata that would like us to support.” It sounds like we might propose that they add support for our proposed isBasedOn property so that the various URLs can be associated with a Uniform Resource Name? In the case of pure cloning (not the production of derivative texts), what would be the downside of adding a
<meta name=”dc.identifier” content=”foo″><meta name=”dc.relation.ispartof” content=”foo”>
to the head of the texts on our dev site before cloning them to production, @ned? Could this get us where we need to go in the short term?
Do we have that version tracking?
I´m creating a complement that do relationships between the translated version of a book (So if book B is the spanish translation of the book A, i will have a link between them) and I would use the version tracking as the base for that.
Yes, when you clone a book, the attribution appears on the cover page.
Can I add manually that attribution?
An also, is not better, in each chaper, to add isBasedOn to the related page? instead of the cover page of the original book?
that is the metadata of one chapter
meta itemprop=‘isBasedOn’ content=‘http://pb.interns.books4languages.com/base-dev1’ id=‘isBasedOn’
but that is the database.
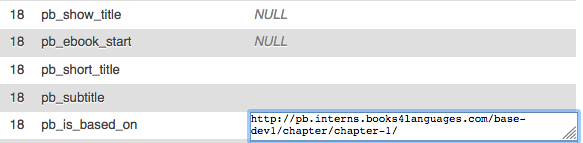
is because you are still developing the feature?
Yes, there’s metadata in the header that’s added book-wide and we need to update the output to handle chapter metadata better.
What about that ??
For anyone following this conversation, some further discussion on this issue is ongoing at this Hypothesis client GitHub issue: https://github.com/hypothesis/client/issues/739